【AI開發也要擁抱DevOps】企業規模化落地AI關鍵是MLOps(上)
臉書隨處可見AI應用的身影,從個人化貼文排序、新聞推薦、廣告推播、人臉標註到仇恨言論過濾,背後都靠AI進行自動化決策。這個開發規模有多大?臉書2016年在自家部落格公開了一個驚人的數據,臉書工程團隊在過去短短一年多的時間內,就訓練了超過100萬個ML模型,更達到每秒600萬次預測。換句話說,平均只要1天,就能訓練出兩、三千個AI模型。為何臉書可以這麼大規模的開發出各種AI應用,關鍵就是2014年著手打造的ML平臺FBLearner Flow,這套AI開發流程,大大減少了AI開發過程中的人工作業。
舉例來說,在FBLearner Flow平臺上,提供了多種預定義ML流程(Pipeline),不同的AI專案能根據需求重複利用這些開發流程,甚至還有一個AI實驗管理UI介面,讓開發者不用寫任何一行前端程式,就能快速建立模型實驗的工作流,管理每日上千次的模型實驗結果,更能線上快速檢視模型輸出、修改標籤與原始數據,甚至能啟動大規模部署工作,並監控模型的表現。
這正是臉書訓練出百萬個AI模型的關鍵,不只降低工程師手動開發作業,還建立可重複使用的ML流程,讓工程師能更專注於特徵工程或模型訓練,藉此提升AI開發速度與模型準確率,甚至,非AI專業的軟體工程師,也能用這個平臺來開發AI應用。勤業眾信風險管理諮詢副總經理廖子毅指出,這個作法,正是近兩年崛起的MLOps概念的體現。
MLOps:一種加速AI落地的人員協作方法
什麼是MLOps?為何這兩年,成了企業AI團隊高度關注的議題?
越來越多企業在AI的發展,走出了實驗階段,開始更大規模的落地應用。為了加速AI開發,開始有企業仿效生產線設計,針對AI開發來建立一個系統性作業流程。
尤其,當AI模型進入持續交付、持續部署、成效監控與迭代更新的階段,要串起整個模型從開發到維運的全生命周期循環,更需要AI模型訓練的資料科學團隊,和負責AI應用部署落地的IT團隊,彼此緊密協作,來維持AI上線後的表現。
兩種不同角色團隊協作的概念,聽起來很熟悉,在軟體開發領域一點都不陌生,就是已經盛行多年的DevOps要解決的課題,運用自動化測試、持續整合、持續部署的工具,推動開發與維運人員更緊密協作,來加速軟體版本迭代更新。近來,國外更直接將DevOps概念延伸到AI開發領域,取ML與DevOps的字尾,創造出「MLOps」的名詞,提倡AI開發也應該納入DevOps文化,透過AI、IT團隊不同角色間的緊密協作,來加速AI落地。
不過,比起DevOps的實踐,是在軟體部署的環節,強調開發與維運人員間的協作,MLOps更提倡AI全生命周期各角色的協作,透過將AI開發流程標準化與簡化,建立起一套系統性協作新方法。
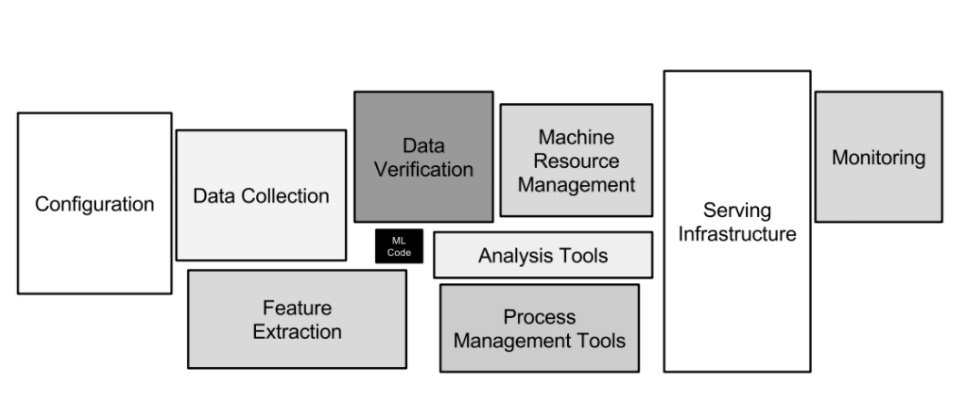
因為相較於軟體開發,AI開發涉及的角色與工作流程都更加複雜。從一張在AI領域流傳已久的ML Pipeline流程圖可以了解,企業要落地一個AI應用,需做的事情遠比訓練一個模型多更多,甚至可以說,整個AI開發系統只有非常少部分的程式碼,是訓練模型所使用,除此之外,還需進行環境配置、資料搜集、特徵工程、資料驗證、運算資源管理、實驗分析、流程管理、部署上線及成效監測等工作,更需眾多不同專業角色來共同協作。
「在ML開發流程中,沒有人可以從頭到尾做完所有事情。」Line臺灣資料工程部資深經理蔡景祥格外有體會的說,AI團隊的不同角色都得各司其職,藉由更緊密的分工協作,在不同開發階段優化AI。
他以自家經驗來解釋,Line臺灣AI團隊中,資料工程師負責資料處理相關工程,ML工程師負責開發AI演算法,前者處理後的資料,會成為後者訓練模型的資料來源。因此,兩種角色需共同定義模型開發所需的資料集,資料處理後的儲存格式與位置,以便後者能直接取用符合需求的資料,無縫進行下階段的開發。
又比如資料科學家雖擅長開發ML模型,但有時為了提升1%的模型準確率,開發出上百MB大小的龐大模型,實際上線後,卻可能拖慢了線上服務的效能。這時,負責分析模型上線實際成效的資料分析師,就需要與資料科學家相互協作,來進行模型精準度與效能之間的取捨。
甚至,蔡景祥指出,ML模型上線後,模型表現還會隨著輸入資料的漂移而逐漸衰變,這時,更需要維運與開發人員緊密協作,在維運端觀察到模型衰變後,交由開發端重新調校模型,甚至得以新特徵、新演算法重新開發準確率更高的模型,再交由維運端部署上線,才能維持模型隨時達到精準預測。
而且,也不只是技術團隊成員間要相互協作,技術單位與業務單位也需要協同合作,透過如模型成效分析工具,量化使用ML後的成效數據,來進一步說服業務單位改用AI預測,確保AI能更有效提供商業面的洞察。
.png)
MLOps流程包含了多種元素在內,包括模型探索、ML Pipeline的部署、模型打包與部署、模型版本控管、模型監控與管理、模型治理、模型安全等議題,都要透過MLOps來實現。(圖片來源/勤業眾信)
AI成熟度高的企業如何大用MLOps?
像臉書、Line都屬於重度使用AI的企業,所以,才會格外重視AI開發的協作文化。勤業眾信一份內部調查報告就指出,不只臉書,MLOps的早期實踐者如Google、Uber、Netflix、Airbnb等企業,都在加速AI應用落地時,面臨了開發瓶頸,並自建ML平臺來克服挑戰。
因為這些企業不僅擁有自己的資料科學家與工程團隊,面臨更多AI開發需求,已經上線的AI應用,更需要一套維運與管理辦法,來隨時提供精準預測。
比如Uber剛開始開發AI時,沒有遵循一套統一的開發流程,將模型部署到生產環境時,也仰賴工程人員客製化開發來上線服務,導致AI開發技能侷限在少數人手上,應用規模也難以擴大。於是,Uber從2015年開始打造ML平臺Michelangelo,要透過標準化的端到端AI開發工作流,讓更多員工能跨過門檻來參與AI開發。
Netflix則是發覺,不同團隊角色之間,常用的分析軟體與程式語言互不相同,增加了AI開發的協作挑戰,因此從2017年Q3開始,試圖深化Jupyter Notebook作為資料處理工具的應用,更整合了支援Jupyter Notebook的相關函式庫或工具,比如互動式介面nteract、用於參數化與執行Jupyter Notebook的函式庫Papermill、Notebook瀏覽與共享工具Commuter以及容器管理平臺Titus,來建構AI開發的基礎建設。
除了國外的應用案例,臺灣也開始有企業實踐MLOps。比如Line臺灣就在去年底完整揭露了韓國總部建置的ML開發平臺ML Universe(簡稱MLU),平臺中整合了不同的開源與自建工具,讓工程師能透過UI的編輯器功能,簡易設定來建立ML Pipeline,訓練完的模型也能快速打包成Docker Image來進行部署,大幅降低了資料科學家與工程團隊間的溝通成本,更提升了開發效率。
或像玉山銀行在2020年時就透露,採用了MLOps協作方法,讓數據模型或新上線的服務,都能即時、彈性回應使用者需求,更打破了AI團隊既有的職務內容框架,讓開發者能從產品端反過來思考ML應用。
「讓AI開發、部署與維運三大團隊,能透過一個標準化的流程來生產AI,建立像是工廠產線的作業流程,就是導入MLOps的重要指標。」廖子毅強調。
勤業眾信更在2021年技術趨勢報告預測中,將MLOps列為今年度十大趨勢之一,今年將有更多企業面臨MLOps的導入需求,這一套AI開發與維運的方法,更將擴大企業落地AI的規模,促成AI開發走向工業化(Industrialized AI)。
文章來源:iThome